 All Projects
All Projects
BookCube
A Django-powered platform for managing and discovering your book collection
Overview
BookCube is a web application that lets readers catalogue their personal book collections, track reading progress, write reviews, and discover new titles. Built with Django and PostgreSQL, it emphasises clean data modelling and a distraction-free reading-log experience.
Problem & Solution
The Problem
Existing book-tracking apps are feature-bloated or lock data inside proprietary ecosystems. There was a need for a self-hosted, open solution where a developer could own their reading data, extend the schema, and expose a clean API for future integrations.
The Solution
Built a monolithic Django application with a well-normalised PostgreSQL schema (Books, Authors, Editions, UserShelves, Reviews). Django's admin and class-based generic views accelerated development of CRUD surfaces, while custom template tags kept the frontend lightweight without a separate JS framework.
Tech Stack
Django's 'batteries included' philosophy — ORM, admin, auth, forms — meant the entire CRUD surface could be built rapidly without assembling a framework from scratch. The MVT pattern keeps business logic testable.
Full-text search (using PostgreSQL's tsvector) powers the book discovery feature without needing an external search engine. Foreign-key constraints ensure referential integrity between books, authors, and user shelves.
Server-side rendering keeps the app fast on low-bandwidth connections and trivially crawlable by search engines — important for a content-heavy catalogue site.
Production deployment uses Gunicorn as the WSGI server behind Nginx for static file serving and reverse proxying, matching standard Django deployment best practices.
Key Features
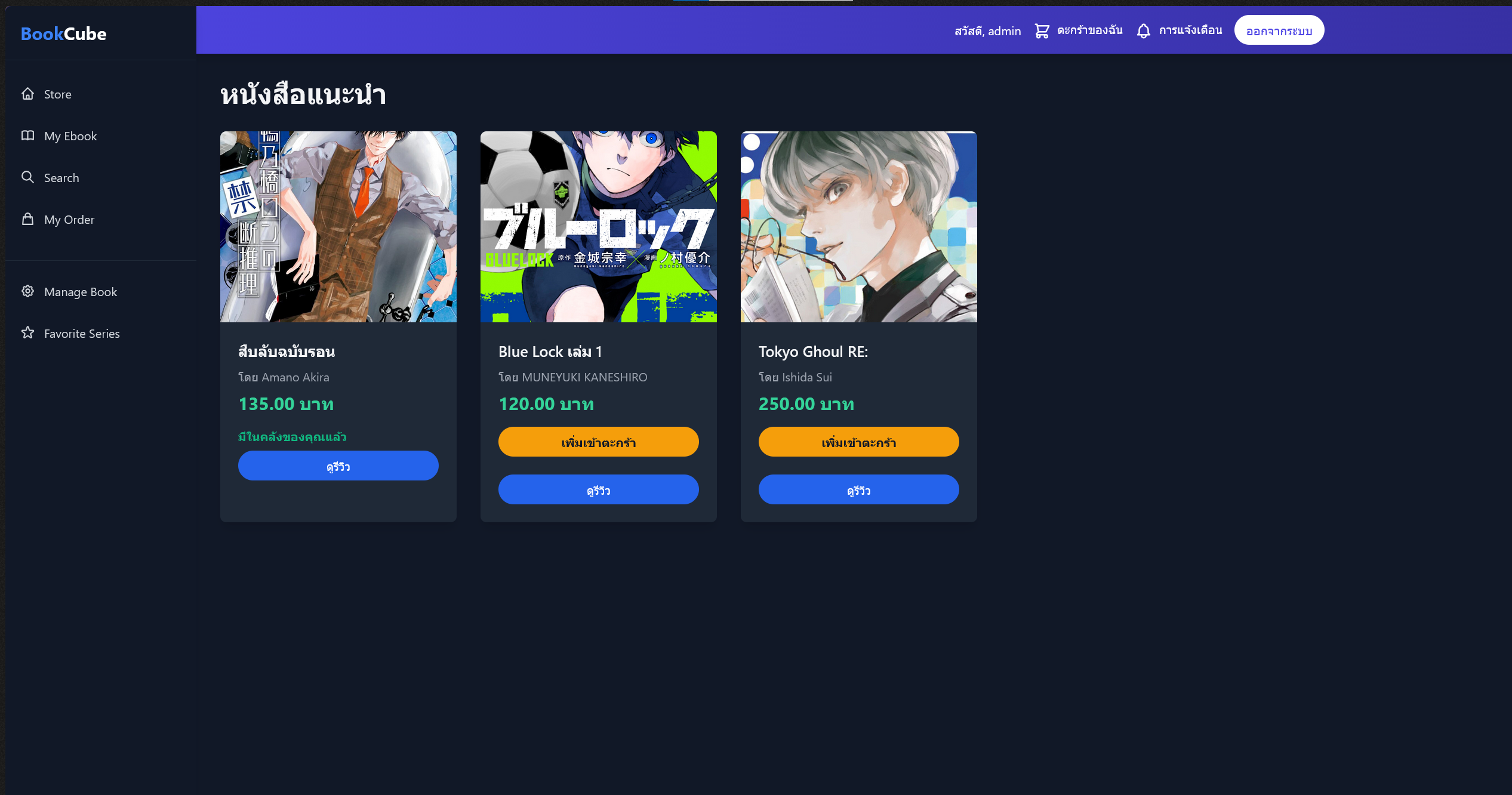
- Personal book shelves: Want to Read, Reading, Read
- Star ratings and written reviews per book
- Reading progress tracker (page / percentage)
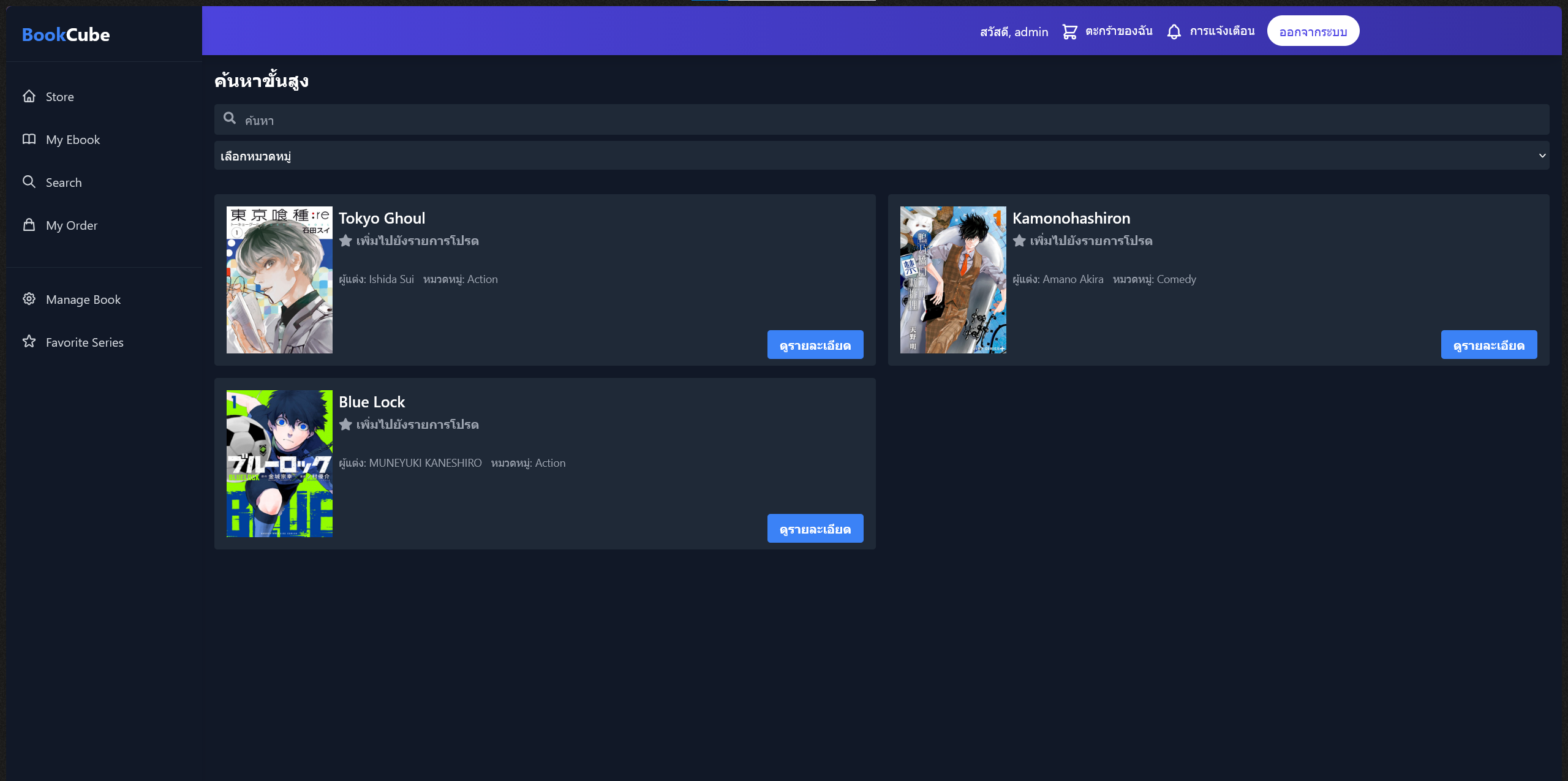
- Full-text search across titles, authors, and ISBNs
- Reading statistics dashboard (books per month, genre breakdown)
- CSV export of personal reading data
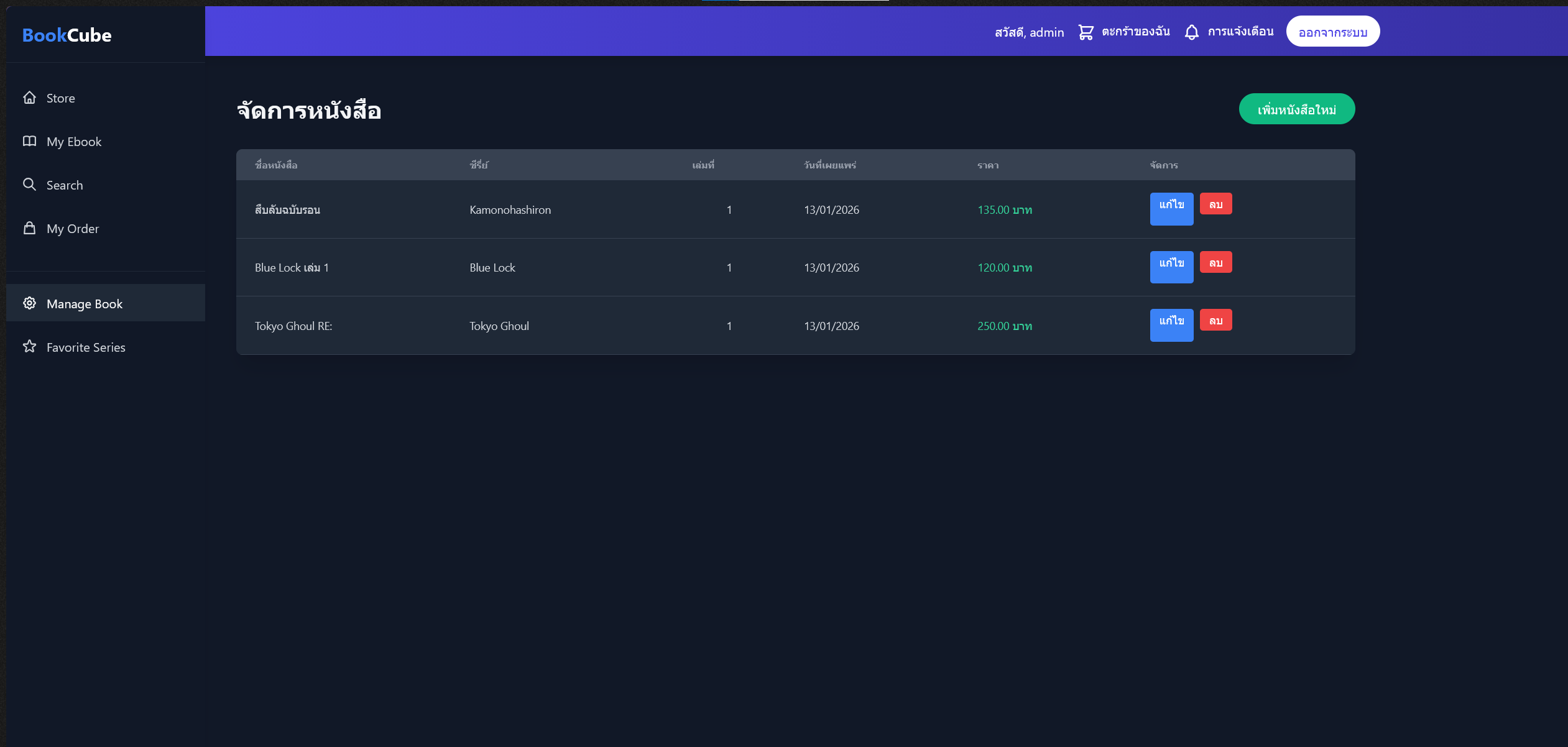
- Django admin panel for content moderation
Challenges & Learnings
Normalising book metadata
Books can have multiple authors, multiple editions, and complex ISBN relationships. Designing a schema that handles many-to-many author relationships and edition variants without duplication required several iterations of the data model.
Full-text search performance
Naive LIKE queries were too slow on a large catalogue. Migrating to PostgreSQL tsvector with GIN indexes improved search latency by an order of magnitude without adding an external service dependency.
Handling duplicate book entries
Users import books from different sources with inconsistent metadata. A deduplication heuristic using ISBN-13 as the primary key, with fuzzy title-author matching as a fallback, keeps the catalogue clean.
Screenshots

BookCube home page
Book catalogue view
Book detail and review
Reading progress tracker
User profile & stats
Search and filter